
What is Apache Kafka?
Apache Kafka is an open-source platform for distributed event streaming which provides high performance for analytics, data integration/transformation for real-time or near real-time applications, and is being used by a lot of companies worldwide.
It works using a publish-subscription method that stores, processes (if needed) and delivers data to subscribers or consumers. Kafka is extremely fast and can handle hundreds of megabytes per second, with hundreds of thousands of messages per second, with latency as low as 2 milliseconds (ms).
What is event streaming?
Event streaming is the ability to capture data from one or more resources – such as Internet of Things (IoT) sensors, databases, or apps –, retain it for a certain period of time for later retrieval, and process, manipulate or route data to different destinations, as required. This can happen in real-time across different technologies.
Who uses Kafka?
Banks, stock exchanges, factories, the retail industry, mobile apps, among others. One thing to have in mind is that Apache Kafka is not for everyone!
There are different flavours of implementation (smaller ones, bigger ones), but real-time is expensive. For use cases where thousands of events per second are generated, processed and consumed, Apache Kafka is a good option as its architecture is robust and reliable, but it might not be cheap to host a Kafka cluster on your own, or to pay for a cloud hosted Apache Kafka service solution.
Why should you know Kafka?
Not everybody has the opportunity to work with Apache Kafka directly, but there are a lot of solutions that use it behind the scenes and it’s nice to have an idea of how it works.
In fact, Apache Kafka is used by over 80% of the Fortune 100 Best Companies to Work For. Some of those giants, as listed by Kafka here, are The New York Times, Pinterest, Adidas, Airbnb, Coursera, Cisco, La Redoute, LinkedIn, Netflix, Oracle, PayPal, Spotify, Tumblr, Yahoo, among many others.
How does Kafka work?
Imagine an event. It could be anything: a notification message, a temperature measurement, GPS coordinates, etc. Events are produced by someone or by an application – it could be, for example, a tweet on the X app (ex-Twitter). These events can be read, used or consumed by someone or by an application. Considering the X app example, we can publish (produce) tweets and also follow someone to read (consume) their tweets (events).
In the Kafka world, events are generated or published by producers and consumed or subscribed by consumers. Events are generated and can be consumed at any time, and need to be stored somewhere. In Kafka, we have topics, which are responsible for storing events, and we can have different types of events stored across different topics.
Considering the publish/subscription method, we could have YouTube or X as applications containing thousands of channels, accounts as topics, content creators publishing videos as producers, messages as events, and people watching or reading content as consumers. In order to handle a massive event production, we need good orchestration, data redundancy and distribution of the workload.
To accomplish this, Kafka has a well-defined architecture that breaks down topics into different partitions. Topics and partitions can be spread across multiple brokers (Kafka servers).
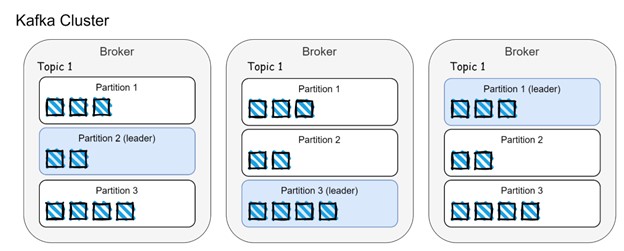
In the image above we can see data distribution across brokers and partitions. Events are distributed between partitions and replicated across brokers. The partition leader is responsible for handling incoming events from producers and client requests from consumers. Remaining partition followers (from other brokers) replicate data from leader partitions and guarantee replicas (brokers) are in-sync, also known as ISR (in-sync-replica).
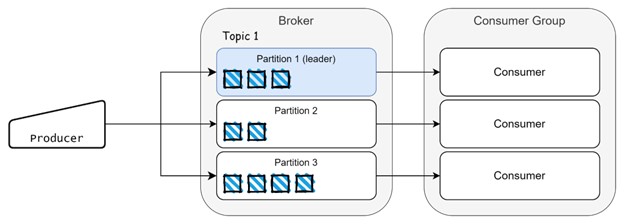
Events are consumed by consumers and we can also have consumer groups, which distribute workload when a large amount of data is generated. Each event stored on a partition has a position and it is known as offset, like a position in an array.
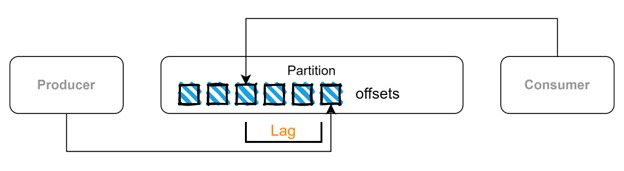
There is a scenario where not all data produced is consumed by consumers and it could happen for different reasons. Going back to the X app example, we may not be able to check all the tweets that are published on the platform, so we’ll have unread tweets. The same can happen to Kafka and this is known as consumer lag. Events are stored in partitions on a sequence, each event has an offset (a position within a partition) and this information is stored on internal topics which hold metadata. So, Apache Kafka “knows” which events were consumed or not, and this lag could be an indication of performance issues.
To orchestrate all this, Apache Kafka has a core dependency called Zookeeper. It keeps track of cluster’s data and coordinates brokers, consumer groups, and elections. It is a prerequisite for some deployment types of the Kafka cluster and must exist prior to Kafka brokers installation. You can have multiple Zookeeper replicas in your Kafka cluster to guarantee high availability, as explained with greater detail here.
Integration with other systems
Kafka can stream data with other systems using Kafka Connect. It is an integration toolkit which contains plugins that can be used with connectors and allows data conversion/transformation.
Kafka Connect architecture contains connectors to create tasks – tasks are used to move data, workers to run tasks, transformers and converters to transform and manipulate data, respectively.
There are two types of connectors:
- Source connectors, which push data from other sources, manipulate/transform it and store it into Kafka topics (e.g., data from a relational database table can be pulled, transformed into JSON format and stored on a topic);
- Sink connectors pull data from Kafka topics, manipulate/transform and push to other data sources. There are several plugins available to manage data integration with different technologies such as Redis, MongoDB, SAP, Snowflake, Splunk, etc.
How can you use Kafka?
There are different flavours of Kafka deployments out there:
-
Manual installation
We can manually install it using Kafka binaries for development and testing on our laptops or containers/servers for production use. For a minimal deployment, we need a Zookeeper instance (if not using KRaft), at least one broker instance and we can use individual scripts available within Kafka binaries for creating topics, starting producers and consumers to generate and consume data. You can easily get started with this quickstart tutorial from Apache.
-
Using operators
Use operators to automatically deploy Kafka clusters and also its extended features (Kafka Connect, Kafka Bridge, Mirror Maker) on Kubernetes/Openshift. The most popular options are Strimzi and Confluent Operator. Operators take care of several manual tasks during cluster installation and also facilitate the usage and maintenance of your cluster when dealing with management of users, topics, configuration changes, etc.
-
On Cloud
Use cloud hosted SaaS solutions like Confluent Cloud, Amazon MSK and others.
References
-
Apache Kafka Org: https://kafka.apache.org/
-
Strimzi: https://strimzi.io/
-
Confluent: https://www.confluent.io/
